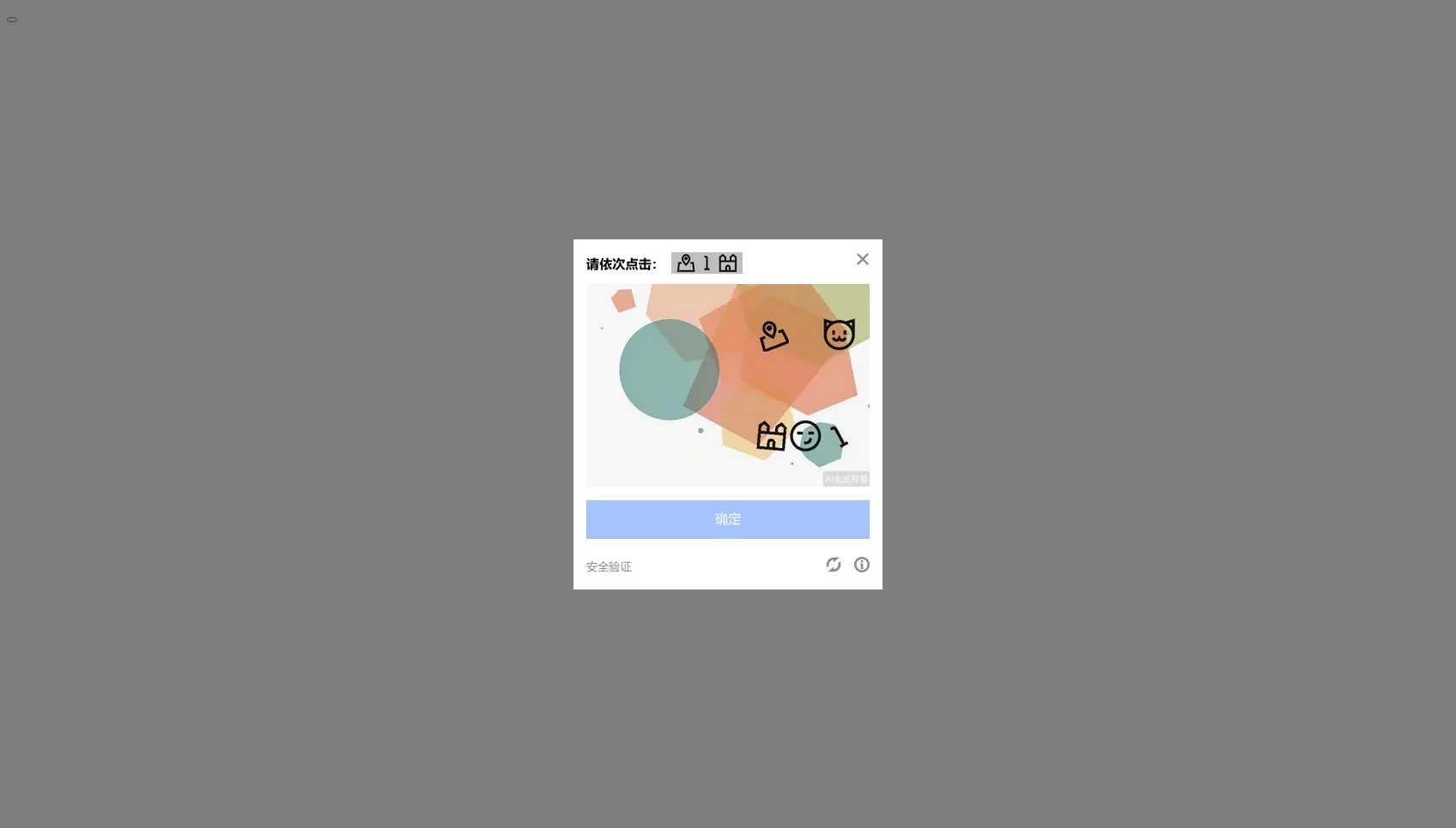
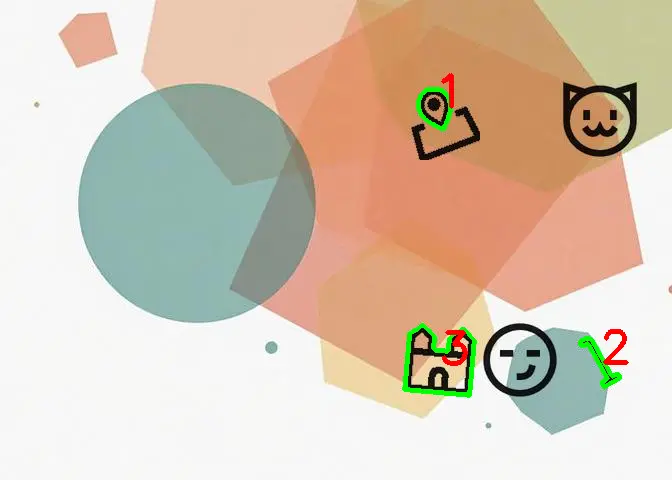
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
| import os, re, json, base64, cv2, numpy as np, requests, argparse
from camoufox.sync_api import Camoufox
class CaptchaSolver:
def __init__(self, headless=True):
self.headless = headless
self.html_path = f"file://{os.path.abspath('captcha.html')}"
def _get_mask(self, img_bytes):
"""从图片字节流生成二值掩码"""
img = cv2.imdecode(np.frombuffer(img_bytes, np.uint8), cv2.IMREAD_COLOR)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
_, mask = cv2.threshold(gray, 60, 255, cv2.THRESH_BINARY_INV)
mask = cv2.morphologyEx(mask, cv2.MORPH_OPEN, np.ones((3, 3), np.uint8))
return img, mask
def _solve_cv(self, top_bytes, bg_bytes):
"""使用计算机视觉解决验证码"""
header = cv2.imdecode(np.frombuffer(top_bytes, np.uint8), cv2.IMREAD_COLOR)
h, w = header.shape[:2]
pw = w // 3
templates = []
for i in range(3):
part = header[:, i * pw : (i + 1) * pw]
_, b = cv2.threshold(
cv2.cvtColor(part, cv2.COLOR_BGR2GRAY),
0,
255,
cv2.THRESH_BINARY + cv2.THRESH_OTSU,
)
if np.sum(b == 255) < b.size / 2:
b = cv2.bitwise_not(b)
cnts, _ = cv2.findContours(
cv2.bitwise_not(b), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE
)
templates.append(max(cnts, key=cv2.contourArea) if cnts else None)
bg_img, mask = self._get_mask(bg_bytes)
bg_cnts, _ = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
bg_cnts = [c for c in bg_cnts if cv2.contourArea(c) > 50]
points = []
for t_cnt in templates:
if t_cnt is None:
continue
best_cnt = min(
bg_cnts,
key=lambda c: cv2.matchShapes(t_cnt, c, cv2.CONTOURS_MATCH_I1, 0.0),
)
M = cv2.moments(best_cnt)
points.append(
(int(M["m10"] / M["m00"]), int(M["m01"] / M["m00"]))
if M["m00"]
else (0, 0)
)
return points, bg_img.shape
def get_token(self, appid):
"""获取验证码 token """
with Camoufox(headless=self.headless) as browser:
page = browser.new_page()
res_data = {"val": None}
page.on(
"console",
lambda m: (
res_data.update({"val": json.loads(m.text[15:])})
if m.text.startswith("CAPTCHA_RESULT:")
else None
),
)
page.goto(f"{self.html_path}?appid={appid}")
page.click("#btn")
page.wait_for_selector(".tencent-captcha-dy__verify-bg-img", timeout=10000)
box = page.locator(".tencent-captcha-dy__verify-bg-img").bounding_box()
top_src = page.locator(
".tencent-captcha-dy__header-answer img"
).first.get_attribute("src")
bg_style = page.locator(
".tencent-captcha-dy__verify-bg-img"
).first.evaluate("el=>window.getComputedStyle(el).backgroundImage")
bg_src = re.search(r'url\("?(.+?)"?\)', bg_style).group(1)
t_bytes = (
base64.b64decode(s=top_src.split(",")[1])
if "base64" in top_src
else requests.get(top_src).content
)
b_bytes = requests.get(bg_src).content
pts, shape = self._solve_cv(t_bytes, b_bytes)
for px, py in pts:
page.mouse.click(
box["x"] + px * (box["width"] / shape[1]),
box["y"] + py * (box["height"] / shape[0]),
)
page.wait_for_timeout(300)
page.click(".tencent-captcha-dy__verify-confirm-btn")
for _ in range(20):
if res_data["val"]:
return res_data["val"]
page.wait_for_timeout(500)
return None
def main():
parser = argparse.ArgumentParser(description='captcha demo')
parser.add_argument('--headless', action='store_true',
help='enable headless mode')
parser.add_argument('--appid', type=str, required=True,
help='captcha\'s appid')
args = parser.parse_args()
solver = CaptchaSolver(headless=args.headless)
token = solver.get_token(args.appid)
if token:
print(f"done!\ncaptcha data:")
print(json.dumps(token, indent=2, ensure_ascii=False))
else:
print("captcha failed!")
if __name__ == "__main__":
main()
|